Notes on Jan 4th Slack Outage


Alex Woods
January 26, 2021
Here are some notes on the root cause analysis from Slack's January 4th outage. This was a massive outage.
I had to make a graph to understand it. I like to think of root causes as a graph.
A lot of people oversimplify it to where there's one smoking gun somewhere that you just have to find and resolve — that was not the case here and it often isn't.
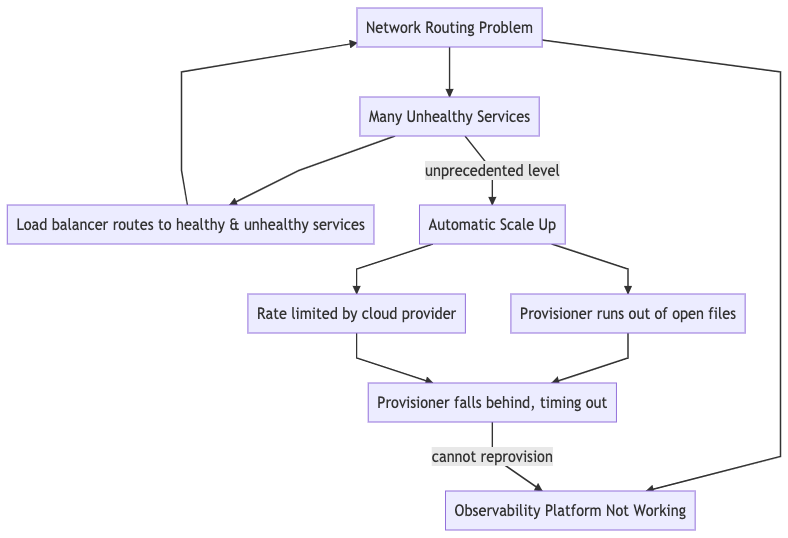
From this point of view, resolving the outage is just picking off nodes from the graph. And that's what they did
- They upped the open file limit on the provisioner
- They worked with the cloud provider to stop the rate limiting
- Meanwhile the cloud provider was working to resolve the routing issues
What can we learn from this?
- Be able to debug your system without your observability platform, at least a little bit.
- Automatic provisioning sounds like a double-edged sword. Some of it's buggy states seem pretty nightmare-ish.
- Microservices have to be pretty tight when it comes to HTTP settings. This is something we experience where I work as well. Connection pooling, timeouts (of various types), and the 95th (and up) percentile requests dominate performance concerns.