Exploring Kubernetes Ingress


Alex Woods
July 09, 2021
At my last job, we had an outage of our ingress controller, Kong.
It had been under memory pressure, and at some point stopped polling for updates to endpoints. Then when we deployed our 2 most important services, they became unreachable.
This confused me—why does it need to know pod's IPs? The service IP is stable, and ingress is an abstraction on top of services.
This diagram in the Kubernetes docs kind of implies that traffic goes through the Service. But it's logical, it's not how traffic actually flows.
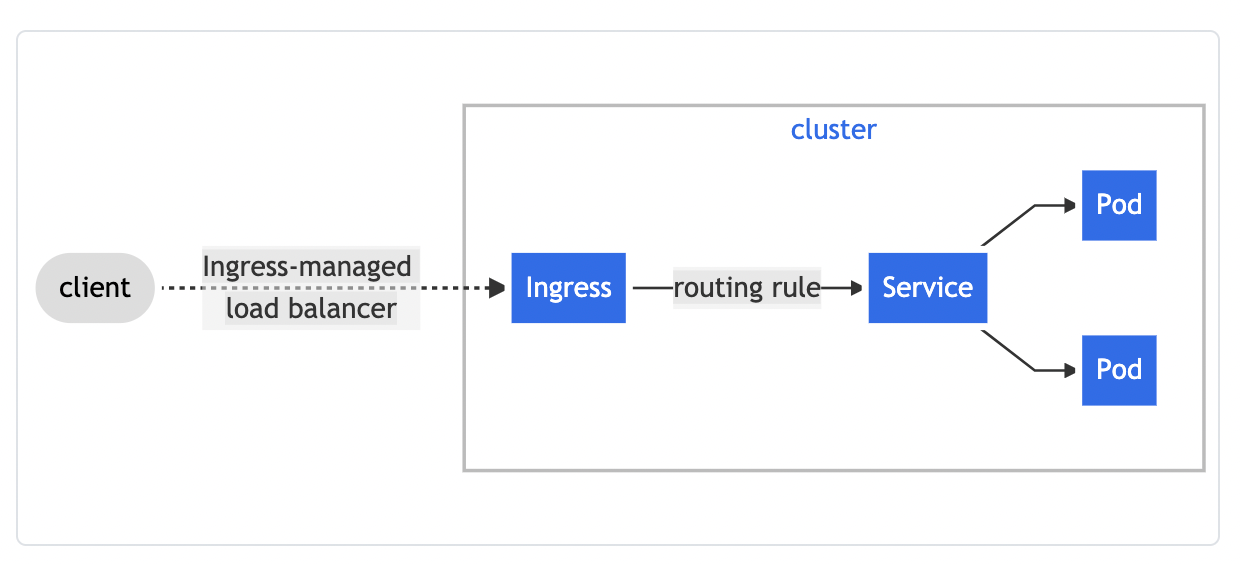
After thinking about it some more, I realized going through the service's IP would be limiting. If the Ingress Controller uses the Service's stable IP, then Kubernetes round-robins requests to the pods, which would take away key functionality that Ingress Controllers try to provide—advanced load balancing algorithms.
How can an Ingress Controller do consistent hashing if it's then routing all requests through the service IP, which then get round-robined?
It can't, so it doesn't go through the service IP. It maintains a list of endpoints, of backends, like any load balancer would. The service is mostly useful for its label selector.
Let's check out the list of endpoints in the ingress-nginx controller.
Deploying ingress-nginx
This was pleasantly simple.
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install ingress-nginx ingress-nginx/ingress-nginx
# Now create an app
kubectl create deployment web --image=gcr.io/google-samples/hello-app:1.0
kubectl expose deployment web --port=8080
Now that we have the web service, let's create an ingress resource and test.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: web
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: atomiccommits.io
http:
paths:
- path: /hello
pathType: Prefix
backend:
service:
name: web
port:
number: 8080
$ curl --header "Host: atomiccommits.io" http://34.69.69.79/hello
Hello, world!
Version: 1.0.0
Hostname: web-65f88c7b8b-txcfv
# Notice how it's the host header and the path to route, not the url and the path
$ curl --header "Host: somethingelse.com" http://34.69.69.79/hello
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
To be clear, that IP address is the IP address of the load balancer created for the ingress controller.
Viewing the endpoints list
Similar to my last example, let's create another deployment and service, called echo-server.
kubectl create deployment echo-server --image=ealen/echo-server
kubectl expose deployment echo-server --port=80
Now, ingress-nginx has a useful kubectl plugin.
Here we can see the endpoints update like I mentioned at the beginning of the article. It wouldn't need these if it was just going to route through the service.
$ k ingress-nginx backends --backend=default-echo-server-80 | jq .endpoints
[
{
"address": "10.4.0.7",
"port": "80"
}
]
$ k scale deployment/echo-server --replicas=5
deployment.apps/echo-server scaled
$ k ingress-nginx backends --backend=default-echo-server-80 | jq .endpoints
[
{
"address": "10.4.0.7",
"port": "80"
},
{
"address": "10.4.0.8",
"port": "80"
},
{
"address": "10.4.1.7",
"port": "80"
},
{
"address": "10.4.2.5",
"port": "80"
},
{
"address": "10.4.2.6",
"port": "80"
}
]
That list of endpoints needs to be up to date
This functionality, of maintaining a list of endpoints to offer more sophisticated load balancing algorithms, is something that always needs to work.
This is what happened in our outage. Our ingress controller had a background thread that polled for endpoints (not unlike kubectl get endpoints --watch), that failed, due to memory pressure.
I spent 15 minutes of downtime checking that Kubernetes Service DNS was still working — but now I know that was more of a rabbit hole, because the Ingress Controller needs to have an updated list of the endpoints.
If you see failures in this regard from your Ingress Controller, figure out a way to monitor that this functionality is always available, and create a playbook entry for how to fix it if it stops working.
For Kong, it's simply restarting it.
And lastly — make sure your ingress controller has more resources requested than it needs.
I love that kubectl plugin
I can't end this without showing how awesome that kubectl plugin is.
# View your nginx configuration
$ k ingress-nginx conf --host=atomiccommits.io
server {
server_name atomiccommits.io ;
listen 80 ;
listen [::]:80 ;
listen 443 ssl http2 ;
listen [::]:443 ssl http2 ;
# the rest is suppressed, there's a lot
# Get a detailed view of your ingresses, with endpoints
$ k ingress-nginx ingresses
INGRESS NAME HOST+PATH ADDRESSES TLS SERVICE SERVICE PORT ENDPOINTS
echo-server atomiccommits.io/echo 34.149.75.86 NO echo-server 80 5
# Lint!
$ k ingress-nginx lint
Checking ingresses...
Checking deployments...
Some other resources I enjoyed while researching this
- Pain(less?) NGINX Ingress
- GCP is doing some interesting things with their native load balancer and how it ties into GCP Networking. See Container-native load balancing and the GKE Network Overview
- Kubernetes NodePort and iptables rules