Exactly Once


Alex Woods
November 20, 2019
In most messaging systems (RabbitMQ, for example) they deal in at-least once delivery. We (should) handle with this by making our systems process messages idempotently, or by de-duplicating.
Exactly once delivery, however, means that within the delivery channel from the service to the messaging system, a message will arrive and be processed exactly once. Sounds simple, right?
Exactly Once Delivery in Kafka
In Kafka, this means that the producer and the Kafka cluster work together to assure that a message is written exactly once to a topic. This is also known as idempotence, which means no matter how many times the producer continues to send a message, it will arrive just once.
In distributed computing, it’s considered a difficult problem (e.g. You Cannot Have Exactly Once Delivery).
At-most once processing is simple - the producer can only send the message once, that is, don’t retry.
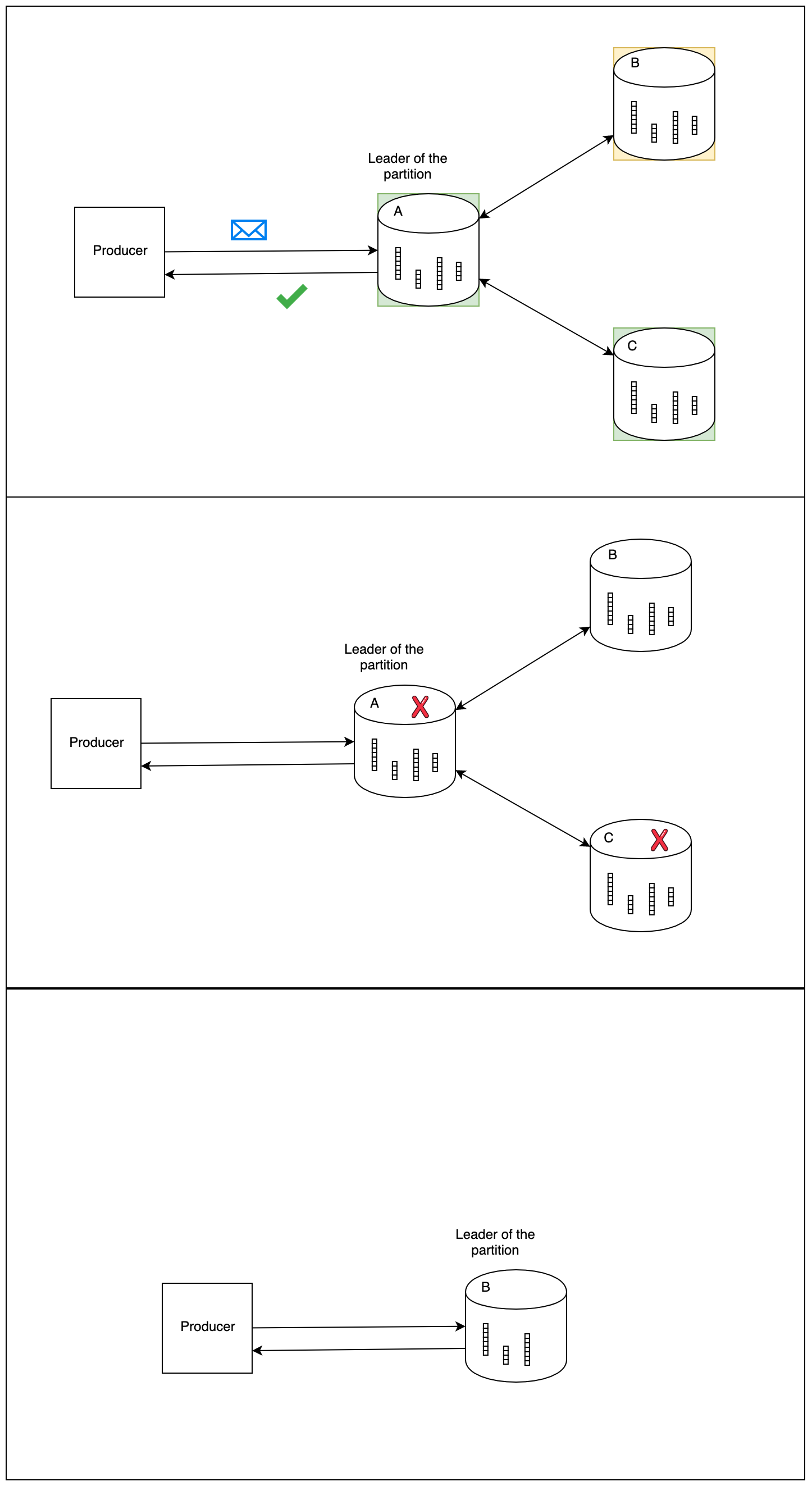
At-least once is a little bit more complicated. All that’s required in Kafka is to set acks=all. The acks config setting controls how many in-sync replicas need to be written to before a message can be considered “committed”. If it’s anything less than all of then, then a message can be written to all in-sync replicas but one, the ack given, all other brokers fail, and the one broker that the write didn’t succeed on is elected the leader (Kafka tolerates n-1 broker failures).
This comic shows what happens if you don’t have acks=all, and broker B doesn’t receive the message, then becomes the leader.
What causes duplication?
In his Idempotent Producer post on Kafka’s Confluence page, Kafka co-creator Jay Kreps mentions that messages can be duplicated in Kafka for 2 reasons:
- A message is written to a topic, and the ack gets lost in the network, causing the producer to retry.
- A consumer reads a message from a topic, crashes, and it is read by the restarting application as well.
He goes on to say that case 2 is solved consumers storing their offset with their output.
Case 1, however, is difficult.
Solution
The first necessary step to enable exactly once processing is to know what producer a message came from. So, producers who have enable.idempotence=true in their config will be given a producer id (a pid).
Producers give a message a sequence number, and the broker can now maintain a current high-water mark for each producer. That is, if the last received message was (pid=5, seq_num=6), the broker will reject anything with a sequence number less than or equal to 6, from the producer with a pid of 5.
Producers that have enable.idempotence=true must also have acks=all set (it will default for you, but if you set another value for acks it will error). Recall why we needed acks=all to guarantee at-least once processing. The new changes simply guard against duplicates. It’s the combination of those two features that give exactly-once semantics.
Note that while using an idempotent producer will result in slight performance degradation, it’s not that bad. And it’s improving.
Relation to TCP
Similarly, TCP also has to guarantee that packets are processed exactly once. Just like Kafka now uses a producer id, TCP can identify the sender of the incoming packet via the connection.
Then, within that connection, it maintains a sequence number in memory, and uses it for order re-assembly and rejecting duplicate packets.
If two processes are communicating across the internet via TCP, and one drops, that’s it. Kafka, on the other hand, is highly reliable because a topic can stay available even with n-1 broker failures.
This means the implementation needed to handle any number of broker failures.
Transactions
A very closely related topic that’s equally exciting and was also presented in KIP-98 is producing messages in a transaction.
With this addition, Kafka allows you to produce to multiple TopicPartitions atomically (all writes succeed or all fail, without side effects). This is a classic example of the distributed computing concept of an atomic broadcast.
It does this by using a TransactionCoordinator, a module in each broker, which manages the logistics of the transaction (e.g. zombie fencing), an internal TransactionLog topic to manage the TransactionCoordinator’s state (similar to the ConsumerOffsets topic). Also introduced with transactions is the notion of a ControlMessage, a message written to a user topic but never exposed to users.
The API to use transactions is extremely simple and when you’re writing a producer you don’t have to worry about the internals.
Summary
Exactly once processing and producing a set of messages in a transaction are two of the most powerful features in Kafka to date. They enable Kafka to work in critical systems like healthcare and finance, and will definitely contribute to its continued growth.