Change Data Capture


Alex Woods
January 16, 2020
In normal architectures, data is trapped in the database. It is only accessible through API's. Normally that's best, because we only want people accessing data in the way we define. Except sometimes it's not. If every microservice has to call every other microservice, that's how you get the incomprehensible web of microservices.
One of the main goals of an event driven architecture is to avoid that. Change data capture is a powerful tool in achieving that goal.
Change data capture is a method of capturing changes at a data source and making them available to other parts of a system.
Change data capture, or CDC, is interesting because it makes data available to the rest of your system. I would argue this is even more useful in the world of microservices, where it’s an anti-pattern for two services to share a database.
Logical Log
A couple years ago, a friend recommended me Martin Kleppman’s article Turning the Database Inside Out. In the article, he talks about how databases use a logical log to manage replication. They do this because in tables, databases hold only the final state, not the steps it took to get there. They do, however, include the steps it took to get there in the write-ahead log.
This log is analogous to Kafka’s distributed log, and a table is the analog of a topic. CDC, therefore, is the natural marriage of these two similarly designed things.
In **log-based CDC**, the kind of change data capture that is slowly becoming the standard, the application takes the data from the write-ahead log, and publishes it to a messaging system, like Kafka.
It Used To Be Worse
For a long time, this was not how we monitored databases for changes. We polled them.
This is called **query-based change data capture**, and it’s still more prevalent than you’d think. For example, Confluent’s JDBC source connector uses this approach. What wrong with this method?
- The closer to real-time we want our data to be, the faster we have to poll. The faster we poll, the greater the strain on the database, and the more your DBA yells at you.
- How would you manage updates? We’ve talked about how tables are really the final outcome of a long event-log. All we can do is compare final outcomes, of which we’ll need one extra set. So we have to maintain an additional set of tables, called staging tables. This might get you off the ground, but it is a bad idea.
That’s not to say **log-based CDC** comes without any difficulties. There are a number of problems, such as parsing the write-ahead log. And not to mention that the log is an internal of the database—it was never meant to be exposed as an API, that’s what SQL is for.
That being said, databases are coming around to log-based CDC. Postgres has a feature that was released in version 10.0 called logical decoding, in which it presents a more easily understandable version of its log. SQL Server has great support for CDC built in. As I’m writing this in 2020, there’s great solutions for many others as well.
Enter Kafka Connect
So far, we’ve been talking about CDC. Let’s turn our attention to Kafka Connect—a tool that allows us setup CDC, although it can do a lot more.
Kafka Connect is one of the three components of Kafka (Kafka Core, Kafka Streams, Kafka Connect). It is used for connecting Kafka to external systems.
Kafka Connect is used to connect Kafka to external systems.
It works by defining an API that then allows the community to go and define **connectors**. These are platform specific; which one we use depends on what external system we want to connect to.
If we want to connect to mysql, we can use the Debezium mysql connector. In this example, we’d say mysql is a **source**, and Kafka is a **sink**.
Similarly, we can also use Kafka Connect to get data from Kafka into an external system. In this case Kafka acts as the **source**, and the external system as the **sink**.
One example of using a **sink** might be Elasticsearch. Say we have a todo items topic, in an event-driven todo app. We can pipe that data into Elasticsearch using an Elasticsearch connector running on Kafka Connect. The beauty of this is that it the connector and Kafka Connect are doing all the work for us in connecting the two systems of Kafka and Elasticsearch. This allows us to focus on business logic, such as the schema our todo item messages should adhere to.
Kafka Connect in an Event-Driven Architecture
Now that we have an understanding of CDC and Kafka Connect, let’s look at some ways we might use these tools in an event-driven architecture.
Unlocking Legacy Systems with CDC
As Ben Stopford mentions in his book Designing Event Driven Systems [2], CDC is a great option to expose data locked down by an old, legacy system, and make it available during an incremental re-write. Here’s a mock-architecture from the book:
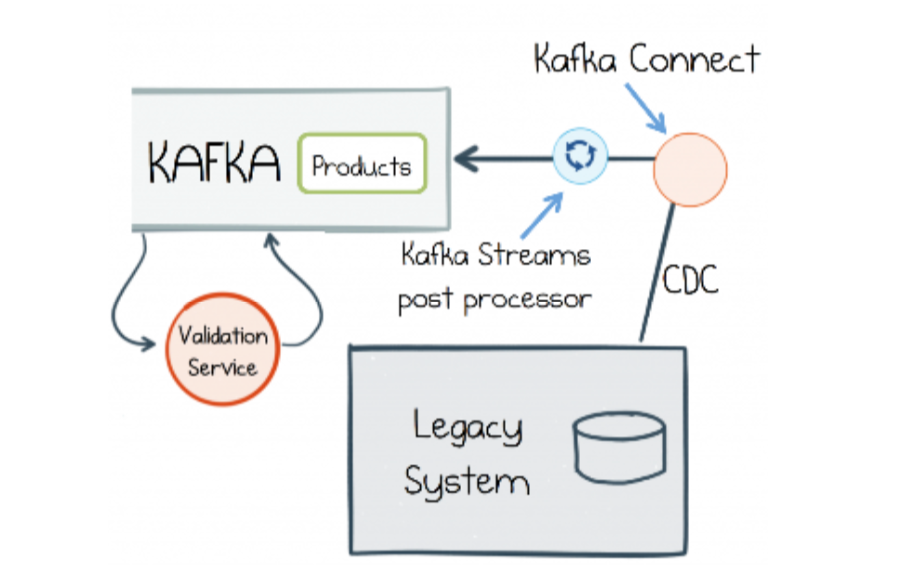
This is nice because it gives us a way to incrementally break apart a legacy system, instead of doing in a one-fell-swoop rewrite. It’s not without problems though—we are taking data out of the database of a system. The database is an internal implementation detail of a system, it’s not a cleanly exposed API. This can make the work difficult, but it still gives us options where before there weren’t so many.
Creating Optimized Views with Kafka Connect
A common pattern in event-driven architectures is creating materialized views.
A materialized view is a query resource that is optimized for reads. You can think about it as a “magically updating cache” [3].
I like to imagine a basic CRUD microservice, but then forget about all mutations. Isolate reading. What would be the absolute best type of data source reads? Perhaps something like a full-text search would give you incredible performance gains and the option to create a richer feature set.
This is roughly the idea of Command Query Responsibility Segregation (CQRS)—using different models for reading and writing. In these systems writes go to completely separate places (like a Kafka topic), and the data eventually makes its way around to the materialized views—which are just queries waiting to happen.
Summary
Today we looked at change data capture—what it is, and a brief foray into how it works.
Then, we turned our attention to Kafka Connect, a tool that allows us to do change data capture, but also a lot more.
If you find these ideas interesting, you can check out Designing Event-Driven Systems, it’s a very thorough treatment of many architecture patterns in event driven systems.
Sources
- About Change Data Capture - SQL Server
- Designing Event-Driven Systems | Confluent
- Stole this phrase from Martin Kleppman