Intro to Bigtable


Alex Woods
May 26, 2020
Lately I've been studying for the GCP Architect exam, and one of the key things I didn't understand was Cloud Bigtable. I had an Anki flashcard with an answer of "a NoSQL database that doesn't support transactions". That's pretty bad. So I decided to read the original Bigtable paper.
What is Bigtable?
Bigtable is a great example of a the NoSQL-type database called a wide column store. Another example of this type of database would be Apache Cassandra. Wide column stores are similar to a relational databases in that they have tables, rows, and columns, but there is not a strict schema that applies to rows in the table.
Fun fact: the Bigtable paper I sat down to read earlier this week is actually the origin of this type of database.
You can also think of it as a persistent, very scalable Hash Map. However, because of the way the data is stored, you want your key to have a certain meaning. Meaning like things are sorted near each other, and vice versa. You want this, because if you're reading multiple rows, you want to avoid a full table scan. e.g.
- sites - domain-reversed URLs. query - "Get me all sub-pages from from
atomiccommits.io" - location - we could get the point on a space-filling curve. query - "get me all houses within this polygon the user drew on Zillow"
There's a good thought exercise. Why is ${longitude}-${latitude} a bad key? (Answer in P.S.).
Fun fact: Bigtable powers Gmail, Google Analytics, and Youtube, as well as a ton of other applications at Google.
Data Model
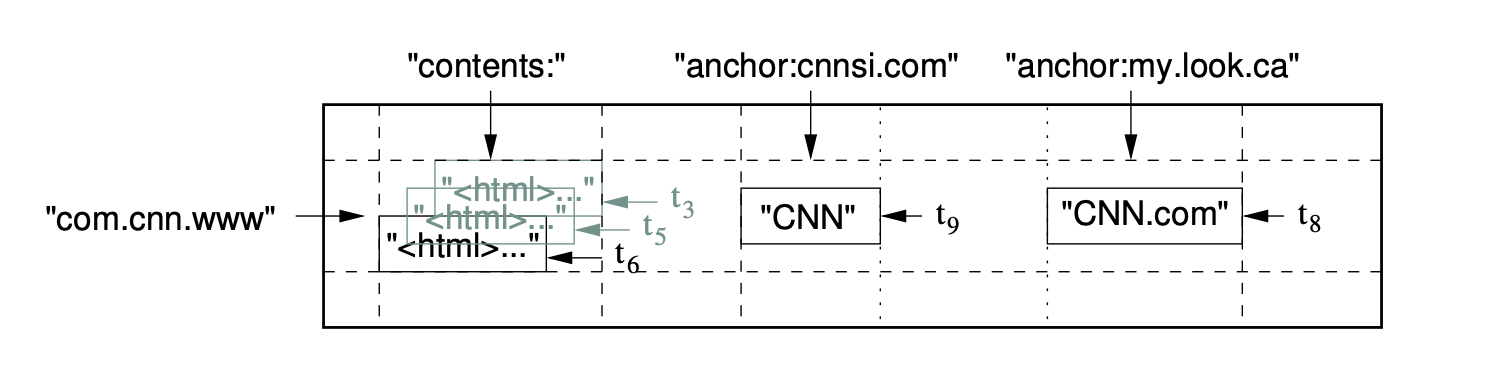
table:
row:
column-family: column-name
First, there are rows. These are similar to a key in Redis.
Second, there are column-families, which are a grouping for columns. This is done for storage and access, and columns should be grouped into a column family when they're logically related (e.g. all artist information about a song on Spotify).
In a given (row, column-family:column), there is a single cell, which would be one piece of data. Note that empty cells occur no storage overhead—hence Bigtable is great for sparse data.
e.g. the row is a domain-reversed url, and there's different column families. There's also different cell versions, indexed by timestamp.
Brief Note on the Internals
I'm going to defer to the official docs on the internals, as this is an intro, but some of the key takeaways for me are:
- Nodes are compute-only, so if you have high CPU usage, adding a node is a simple way to get that down. However, keeping costs under control does mean having the right number of nodes.
- The number of clusters is your dial for changing replication (and thus durability and availability) per instance. See here for more.
Bigtable is not that cheap to run. My wife was eyeing the Cloud console billing page with me as I wrote this, telling me to finish up.
Scale
Bigtable is linearly scalable. Adding a node can increase how many queries per second (by about 10K) your system can handle. There are lots of production systems using Bigtable to store at least terabytes of data.
In case you feel like hindering performance, you can
- Design a bad schema
- Put large amounts of data in your rows
- Create too many cells, and not define a garbage collection policy.
- Not have enough nodes
- Unnecessarily use HDD storage. Here's why you might want HDD.
Uses and Strengths
Bigtable is very strong for some pretty specific use cases, here were some of the ones I found
- IoT / Machine Data
- Server Metrics
- Time Series
- Geospatial
- Financial Data
and the one I found the most interesting
- web data
On that note..
Example: Sitebuilder
We're going to create an API for a front end that builds websites. Our API will allow us to
- Create a site
- Update a site
- Get a site
- Get all sites
Because we're using Bigtable, we'll get some cool features for free on top of that.
- A version history of a site is maintained — upon updating, it just creates a new version. And when we get a site, we can specify a max number of versions to return.
- Get all sites with a prefix search — since we're using reverse domain name notation as the keys for our sites in our Bigtable (this is common pattern), we can use this to get a quick read of all of the sites for some domain.e.g. "Give me all the sub-pages for this site,
blog.atomiccommits.io/kotlin". Well, the reverse-domain name notation version of that isio.atomiccommits.blog/kotlin, so using our API we would do
curl http://localhost:3000/sites?prefix=io.atomiccommits.blog/kotlin
Schema
There are two tables. One called sites, which is the core table with all of our site information, and a second called site-ids, which is a lookup table from a UUID to the key in sites. site-ids really just exists to provide a more normal REST API.
sites
(key) <domain-reversed-url>:
content:
html
meta:
id
site-ids
(key) <uuid>:
a:
a:
<domain-reversed-url> // key of sites
The existence of two tables here is actually a good example of indexing. In a relational database, we would just have the UUID be the primary key, and the domain-reversed URL be another column, and we'd build an index on that column.
In Bigtable, there's one (and only one) index—on the row key. So you "index" by creating another table with redundant information.
Another odd pattern that might jump out at you is that I have a column-family:column of a:a in the site-ids table. This is because I really just need a 1D HashMap in this case, not a 2D one. And instead of going and using Redis or Memcache, I just made the column-family:column as small and unobstrusive as possible. I stole this pattern from Music Recommendations at Scale | Spotify. I like the idea; it's pragmatic and creates as little noise as possible.
Bigtable API
My example is written in Go—I needed to mix it up from Node.js. (Let me know if you have any suggestions on how to improve my Go code, I'm pretty new to it.)
Let's look at the function for creating a site.
func CreateSite(c context.Context, p *Page) (Page, error) {
siteId := uuid.New().String()
invertedUrl := util.InvertUrl(p.Url) // domain-reverse the url
sites := db.Client.Open("sites")
siteMutation := bigtable.NewMutation()
siteMutation.Set("meta", "id", bigtable.Now(), []byte(siteId))
siteMutation.Set("content", "html", bigtable.Now(), []byte(p.Html))
sites.Apply(c, invertedUrl, siteMutation)
siteIds := db.Client.Open("site-ids")
siteIdMutation := bigtable.NewMutation()
siteIdMutation.Set("a", "a", bigtable.Now(), []byte(invertedUrl))
siteIds.Apply(c, siteId, siteIdMutation)
return Page{Url: util.InvertUrl(invertedUrl), Html: p.Html, Id: siteId}, nil
}
We create and apply two mutations which correspond to creating new entries in the table (either for an existing key or a new one, same API). Update is very similar. Note that these don't happen in a transaction, because Bigtable doesn't support transactions.
I'm inverting the inverted url because domain reversing a domain-reversed url results in the original url. Here's my test of that statement.
The read functions are a little cooler, because we get the version functionality and the prefix search functionality. Here's the queries
// Read 1 site query
sites := db.Client.Open("sites")
row, _ := sites.ReadRow(c, siteId, bigtable.RowFilter(bigtable.ColumnFilter("html")))
// Read all sites query, with the prefix scan
rr := bigtable.PrefixRange(prefix)
sites.ReadRows(c, rr, func(r bigtable.Row) bool {
pages = append(
pages,
Page{
Url: util.InvertUrl(r.Key()),
Html: string(r["content"][0].Value),
Id: string(r["meta"][0].Value),
})
return true // continue
})
If you're curious of a demo or how to set up and run the API, look in the README on Github.
What is Bigtable not good for?
It does not support multi-row transactions. So it's a bad choice for an OLTP application.
Also, if you are going to have a relatively small amount of data, it's probably not worth it. There is an overhead—it's expensive.
How does Bigtable relate to Cloud Datastore?
Cloud Datastore is built upon Bigtable, but with features that move towards a typical relational database. Features like
- Secondary indexes
- ACID transactions
- SQL-like query language
There's pricing differences as well. The gist is that for big data / frequent access Bigtable is better.
Conclusion
I hope you enjoyed this article. Let me know if there's anyway I can improve it, or any inaccuracy you find, I'll be happy to correct it.
Also, if you use Bigtable, email me and let me know about your experience; I'm very curious about it. That might be a good reason to finally set up Disqus comments on this thing..
P.S. ${longitude}-${latitude} is a bad key because when Bigtable sorts the strings, the rows that correspond to D.C. and Lima would be next to each other, but they're nowhere near each other. The worst thing we can do in Bigtable is a full table scan.